
The 15 AI Agent Design Patterns Every Engineer Should Know (With Production Examples)
A field guide for engineers who want the right pattern, not the most impressive one.

There is a predictable arc to how teams build agentic systems. It starts simply: one prompt, one loop, a few tools. Then reality intervenes — new requirements, more teams, compliance, harder workflows. Suddenly, one loop is carrying multiple concerns inside an oversized system prompt. The architecture debate begins: keep extending it, move to multi-agent systems, or introduce a framework? Usually, the team is split.
This guide is for the moment before that debate takes over. It covers the major patterns used in production agentic systems, when each one earns its place, and the trade-offs involved. The examples use class-based Python — code you would actually review in a pull request, not demo-grade snippets.
We will cover:
Pattern 1: Single-Agent (Month 1)
Pattern 2: Multi-Agent Sequential (Month 3)
Pattern 3: Multi-Agent Parallel (Month 5)
Pattern 4: Loop (Month 6)
Pattern 5: Review and Critique
Pattern 6: Iterative Refinement
Pattern 7: Coordinator (Month 9)
Pattern 8: Hierarchical Task Decomposition (Month 11)
Pattern 9: Swarm (Month 12)
Pattern 10: ReAct (Reason and Act) (Month 13)
Pattern 11: Human-in-the-Loop (Month 14)
Pattern 12: Plan-and-Execute (Month 15)
Pattern 13: Reflexion (Month 16)
Pattern 14: Custom Logic (Month 18)
Pattern 15: Event-Driven Agent
We will follow a single company: an e-commerce platform called Vend. Their AI platform team starts with one support agent and, over eighteen months, evolves into a system spanning multiple patterns. Each shift happened for a reason. Understanding the reason behind the decision matters more than memorizing the pattern itself.
Before You Pick a Pattern
A task justifies an agent when at least one of these is true:
A single model call cannot produce a reliable result.
The model must choose between tools or data sources at runtime.
The task requires planning, validation, or iterative refinement.
The workflow contains uncertainty that cannot be expressed through static business logic.
A task usually does not justify an agent when the input-to-output path is predictable.
Tasks like summarization, classification, templated generation, and simple extraction are often faster, cheaper, and more reliable as direct model calls.
Wrapping them in an agent typically adds latency, failure points, and unnecessary complexity without delivering meaningful value.
Shared Infrastructure
All examples use the following base structure. In production you would add retries, request IDs, structured logging, rate-limit handling, budget tracking, policy checks, and durable state.
import json
import os
import asyncio
from dataclasses import dataclass, field
from typing import Any
from openai import OpenAI
client = OpenAI(api_key=os.environ["OPENAI_API_KEY"])
MODEL = "gpt-4o"
@dataclass
class AgentResult:
content: str
tool_calls: list[dict] = field(default_factory=list)
metadata: dict = field(default_factory=dict)
class BaseLLMAgent:
def __init__(self, model: str = MODEL):
self.client = client
self.model = model
def _text(self, system: str, user: str) -> str:
response = self.client.responses.create(
model=self.model,
input=[
{"role": "system", "content": system},
{"role": "user", "content": user},
],
)
return response.output_text
def _structured(self, system: str, user: str, schema: dict[str, Any]) -> dict[str, Any]:
response = self.client.responses.create(
model=self.model,
input=[
{"role": "system", "content": system},
{"role": "user", "content": user},
],
text={"format": {"type": "json_schema", "name": "output", "schema": schema, "strict": True}},
)
return json.loads(response.output_text)
Pattern 1: Single-Agent [Month 1]
The AI team gets its first task: let customers ask questions about their orders without waiting for a human agent. The workflow is straightforward — look up an order, check shipping status, create a support ticket if needed. Three tools, one clear responsibility
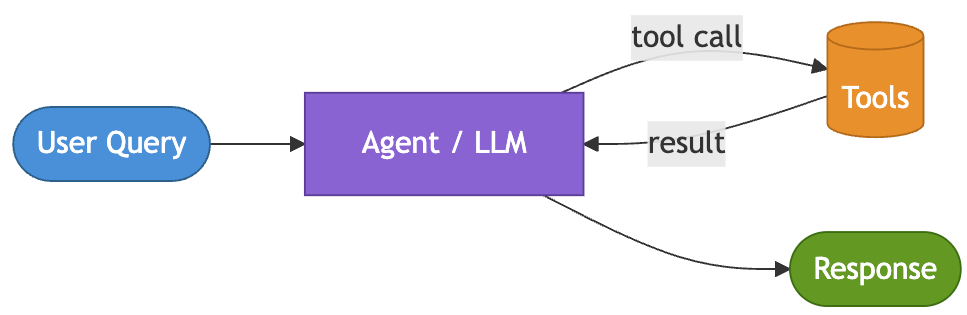
This is where most agentic systems should begin: one model, one system prompt, and a bounded set of tools. The model decides which tool to invoke, observes the result, and continues until it has enough context to respond. Simpler systems are easier to reason about, debug, and improve.
import json
from openai import OpenAI
from dataclasses import dataclass
@dataclass
class OrderContext:
order_id: str
status: str
carrier: str
eta: str
@dataclass
class SupportTicket:
ticket_id: str
order_id: str
reason: str
class CustomerSupportAgent(BaseLLMAgent):
"""Single-agent that handles order support by choosing its own tools."""
SYSTEM_PROMPT = (
"You are a customer support agent. Use tools when order data is needed. "
"Do not invent order status. If the issue cannot be resolved from tools, create a ticket."
)
TOOLS = [
{
"type": "function",
"name": "get_order",
"description": "Fetch order status by order ID.",
"parameters": {
"type": "object",
"properties": {"order_id": {"type": "string"}},
"required": ["order_id"],
"additionalProperties": False,
},
},
{
"type": "function",
"name": "create_support_ticket",
"description": "Create a support ticket when the issue cannot be answered from order data.",
"parameters": {
"type": "object",
"properties": {
"order_id": {"type": "string"},
"reason": {"type": "string"},
},
"required": ["order_id", "reason"],
"additionalProperties": False,
},
},
]
def _get_order(self, order_id: str) -> dict:
# Replace with real DB/API call
return {"order_id": order_id, "status": "shipped", "carrier": "DHL", "eta": "2026-06-01"}
def _create_support_ticket(self, order_id: str, reason: str) -> dict:
return {"ticket_id": "SUP-1042", "order_id": order_id, "reason": reason}
def _dispatch_tool(self, name: str, args: dict) -> dict:
if name == "get_order":
return self._get_order(**args)
if name == "create_support_ticket":
return self._create_support_ticket(**args)
return {"error": f"Unknown tool: {name}"}
def run(self, user_message: str, max_turns: int = 4) -> str:
messages = [
{"role": "system", "content": self.SYSTEM_PROMPT},
{"role": "user", "content": user_message},
]
for _ in range(max_turns):
response = self.client.responses.create(
model=self.model, input=messages, tools=self.TOOLS
)
tool_calls = [item for item in response.output if item.type == "function_call"]
if not tool_calls:
return response.output_text
messages += response.output
for call in tool_calls:
result = self._dispatch_tool(call.name, json.loads(call.arguments))
messages.append({
"type": "function_call_output",
"call_id": call.call_id,
"output": json.dumps(result),
})
return "I could not complete the request safely within the tool budget."
When to Use and When it Breaks:
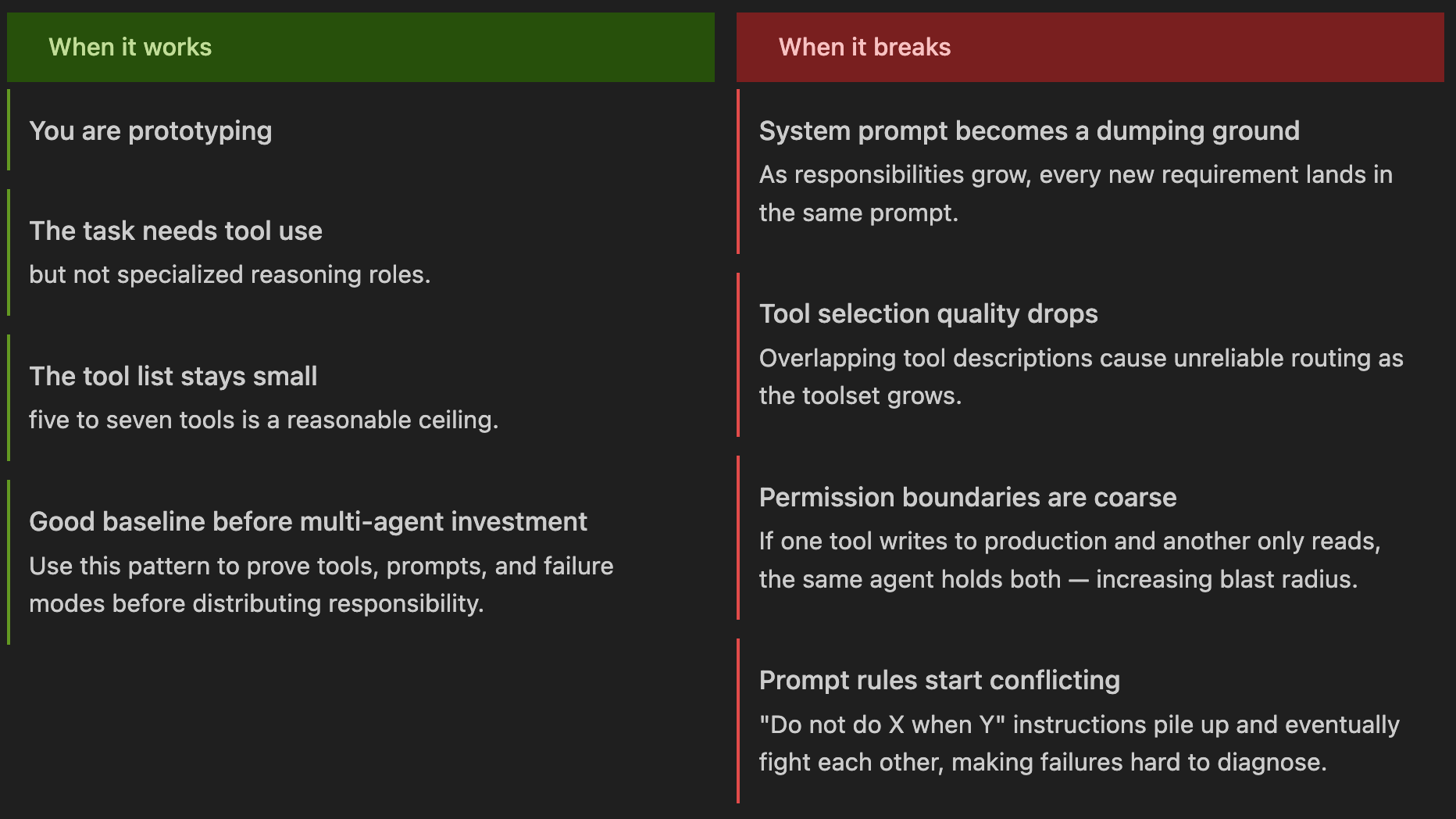
Pattern 2: Multi-Agent Sequential [Month 3]
Legal operations receives vendor contracts, and the review process is well-defined: extract obligations, identify risk clauses, and draft a summary for the procurement manager. The sequence never changes, and each step produces exactly what the next step requires.

The sequential pattern runs specialized agents in a fixed order. Each agent has a narrow prompt and a clear input/output contract. Orchestration is deterministic — reasoning happens within each stage, not in the routing between agents, making the process predictable and auditable.
from dataclasses import dataclass
@dataclass
class ContractAnalysis:
obligations: str
risks: str
review_packet: str
class ContractIntakePipeline(BaseLLMAgent):
"""Sequential pipeline: extract → assess → draft."""
def _extract_obligations(self, contract_text: str) -> str:
return self._text(
"Extract concrete obligations from vendor contracts. "
"Return only obligations with dates, parties, or deliverables.",
contract_text,
)
def _assess_risks(self, obligations: str) -> str:
return self._text(
"You are a contract risk reviewer. Identify operational, financial, and compliance risks. "
"Do not provide legal advice.",
obligations,
)
def _draft_review_packet(self, contract_text: str, obligations: str, risks: str) -> str:
return self._text(
"Prepare a concise contract review packet for a procurement manager. "
"Include obligations, risks, and questions for counsel.",
f"Contract:\\\\n{contract_text}\\\\n\\\\nObligations:\\\\n{obligations}\\\\n\\\\nRisks:\\\\n{risks}",
)
def run(self, contract_text: str) -> ContractAnalysis:
obligations = self._extract_obligations(contract_text)
risks = self._assess_risks(obligations)
packet = self._draft_review_packet(contract_text, obligations, risks)
return ContractAnalysis(obligations=obligations, risks=risks, review_packet=packet)
When to Use and When it Breaks:

Pattern 3: Multi-Agent Parallel [Month 5]
The on-call team gets a midnight alert: checkout is failing. Three signals need immediate investigation — application logs, infrastructure metrics, and recent deployments. These are genuinely independent sources of information. Running them sequentially wastes the first few minutes that matter most during an incident.
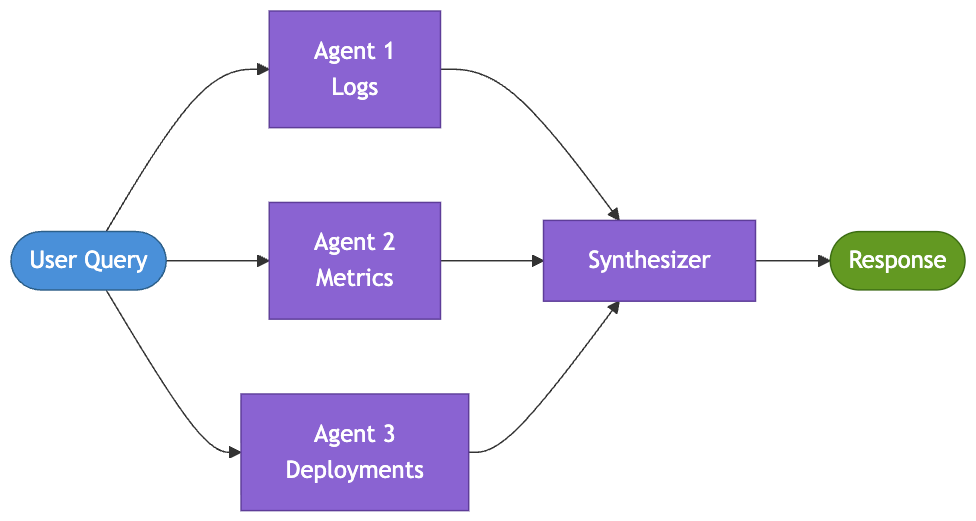
The parallel pattern distributes independent subtasks across multiple agents simultaneously and combines their outputs into a single view. When tasks do not depend on one another, parallelism reduces latency and speeds up decision-making under pressure.
import asyncio
from dataclasses import dataclass
@dataclass
class IncidentReport:
log_analysis: str
metric_analysis: str
deployment_analysis: str
synthesis: str
class IncidentTriageAgent(BaseLLMAgent):
"""Parallelizes three specialist agents then synthesizes a root-cause hypothesis."""
async def _ask_specialist(self, role_prompt: str, incident: str) -> str:
return await asyncio.to_thread(self._text, role_prompt, incident)
async def run(self, incident_description: str) -> IncidentReport:
log_prompt = "You inspect application logs. Identify error patterns with timestamps and request IDs."
metric_prompt = "You inspect metrics. Identify saturation, latency spikes, and traffic anomalies."
deploy_prompt = "You inspect recent releases. Flag risky changes that align with the reported symptoms."
log_view, metric_view, deploy_view = await asyncio.gather(
self._ask_specialist(log_prompt, incident_description),
self._ask_specialist(metric_prompt, incident_description),
self._ask_specialist(deploy_prompt, incident_description),
)
synthesis = self._text(
"You are the incident commander. Synthesize evidence from three specialist views. "
"State confidence level and the single safest next action.",
f"Logs:\\\\n{log_view}\\\\n\\\\nMetrics:\\\\n{metric_view}\\\\n\\\\nDeployments:\\\\n{deploy_view}",
)
return IncidentReport(
log_analysis=log_view,
metric_analysis=metric_view,
deployment_analysis=deploy_view,
synthesis=synthesis,
)
When to Use and When it Breaks:

Pattern 4: Loop [Month 6]
The data engineering team ingests CSV extracts from third-party suppliers, where data quality is often inconsistent. They need an agent that can profile the data, propose a cleaning strategy, validate it against quality checks, and retry when needed.

The loop pattern repeats a sequence of agent steps until an exit condition is satisfied. The challenge is not the loop itself — it is defining a reliable stopping condition. Without one, you end up with runaway costs, unpredictable behavior, and no guarantee of termination.
import json
from dataclasses import dataclass
@dataclass
class CleaningResult:
plan: str
rounds_taken: int
passed: bool
class DataQualityRepairAgent(BaseLLMAgent):
"""Iteratively proposes and judges cleaning plans until quality passes or budget is exhausted."""
QUALITY_SCHEMA = {
"type": "object",
"properties": {
"passes": {"type": "boolean"},
"reason": {"type": "string"},
"remaining_issues": {"type": "array", "items": {"type": "string"}},
},
"required": ["passes", "reason", "remaining_issues"],
"additionalProperties": False,
}
def _profile(self, sample_rows: str) -> str:
return self._text(
"Profile tabular data. Identify missing values, inconsistent formats, "
"suspicious categories, and likely schema issues.",
sample_rows,
)
def _propose_plan(self, profile: str, previous_plan: str | None) -> str:
return self._text(
"Propose a safe pandas cleaning plan. Prefer reversible transformations. "
"Do not drop columns unless explicitly justified.",
f"Profile:\\\\n{profile}\\\\n\\\\nPrevious attempt:\\\\n{previous_plan or 'None'}",
)
def _judge(self, profile: str, plan: str) -> dict:
return self._structured(
"Judge whether the cleaning plan addresses the data profile without unsafe assumptions.",
f"Profile:\\\\n{profile}\\\\n\\\\nPlan:\\\\n{plan}",
self.QUALITY_SCHEMA,
)
def run(self, sample_rows: str, max_rounds: int = 3) -> CleaningResult:
profile = self._profile(sample_rows)
plan = None
for round_num in range(1, max_rounds + 1):
plan = self._propose_plan(profile, plan)
verdict = self._judge(profile, plan)
if verdict["passes"]:
return CleaningResult(plan=plan, rounds_taken=round_num, passed=True)
# Append reviewer feedback to the profile so the next proposal is informed
profile += f"\\\\nReviewer feedback (round {round_num}):\\\\n{json.dumps(verdict)}"
return CleaningResult(plan=plan, rounds_taken=max_rounds, passed=False)
When to Use and When it Breaks:
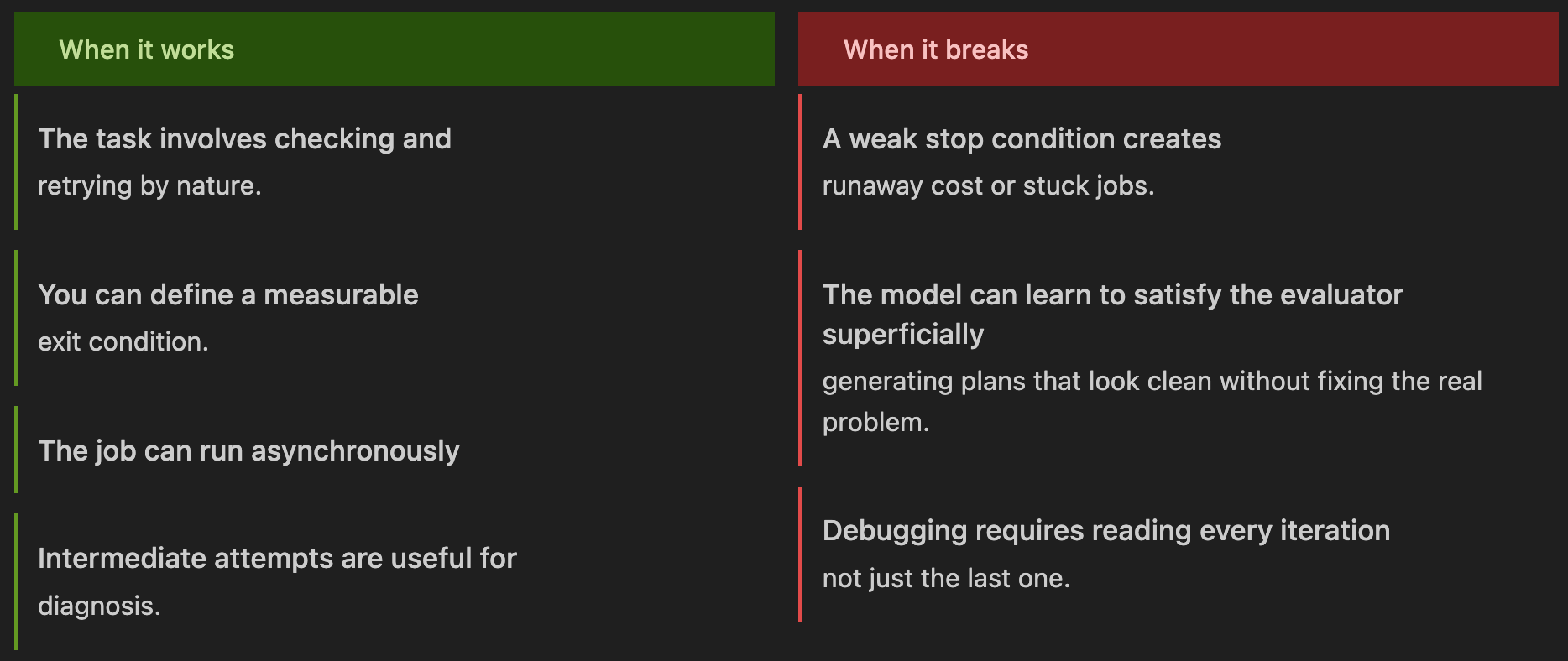
Note: This is a simplified example of using LLM-as-a-Judge to review and approve another model’s response.
In this example, the flow uses a loop with a boolean approval flag. In practice, there are many variations. Instead of a binary decision, the judge can return a score, or provide structured feedback that the generator uses to improve the next iteration. The design space here is broad, so I am intentionally keeping the implementation lightweight.
✅ Pattern 5: Review and Critique → A judge agent reviews the output, critiques it, and provides actionable feedback on what should improve.
✅ Pattern 6: Iterative Refinement → The system runs in a feedback loop with a score threshold. Until the response crosses the required quality bar, the generator continues refining the output.
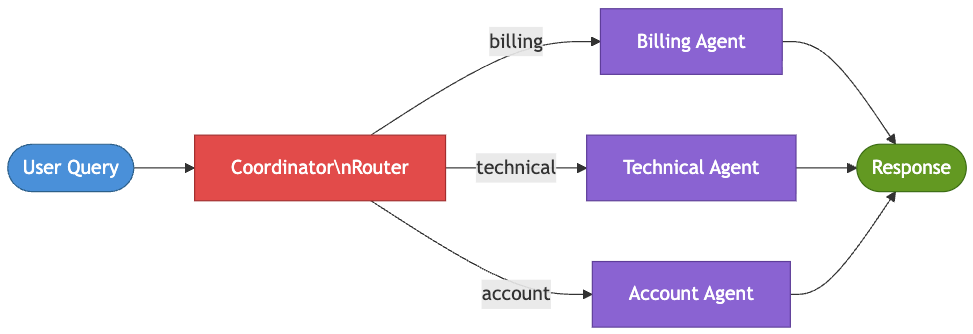
Pattern 7: Coordinator [Month 9]
Support has expanded into five distinct departments: billing, technical support, account management, shipping, and fraud. A single agent trying to handle all of them ends up relying on a 3,000-word system prompt, eventually struggling with edge cases and conflicting instructions. At that point, the issue is no longer prompt quality — different request types genuinely require different context, tools, and decision-making logic.
The coordinator pattern introduces a central routing agent that directs incoming requests to specialized agents. Unlike sequential or parallel workflows, the execution path is determined dynamically at runtime, based on the nature of the request. This keeps individual agents focused, reduces prompt complexity, and improves reliability as the system grows.
from dataclasses import dataclass
@dataclass
class RoutingDecision:
specialist: str
reason: str
class SupportCoordinator(BaseLLMAgent):
"""Routes support messages to the right specialist agent."""
ROUTING_SCHEMA = {
"type": "object",
"properties": {
"specialist": {
"type": "string",
"enum": ["billing", "technical", "account", "shipping", "fraud"],
},
"reason": {"type": "string"},
},
"required": ["specialist", "reason"],
"additionalProperties": False,
}
SPECIALISTS: dict[str, str] = {
"billing": "You handle billing support. Request invoice IDs when needed. Never quote prices from memory.",
"technical": "You handle technical troubleshooting. Ask for logs and environment details when needed.",
"account": "You handle account access issues. Never request passwords or raw secrets.",
"shipping": "You handle delivery and tracking questions. Escalate customs issues to a human agent.",
"fraud": "You handle suspected fraud reports. Collect evidence carefully. Never accuse the customer.",
}
def _route(self, message: str) -> RoutingDecision:
result = self._structured(
"Route this support request to exactly one specialist based on the primary issue.",
message,
self.ROUTING_SCHEMA,
)
return RoutingDecision(**result)
def _run_specialist(self, specialist_prompt: str, message: str) -> str:
return self._text(specialist_prompt, message)
def run(self, message: str) -> str:
decision = self._route(message)
specialist_prompt = self.SPECIALISTS[decision.specialist]
return self._run_specialist(specialist_prompt, message)When to Use and When it Breaks:

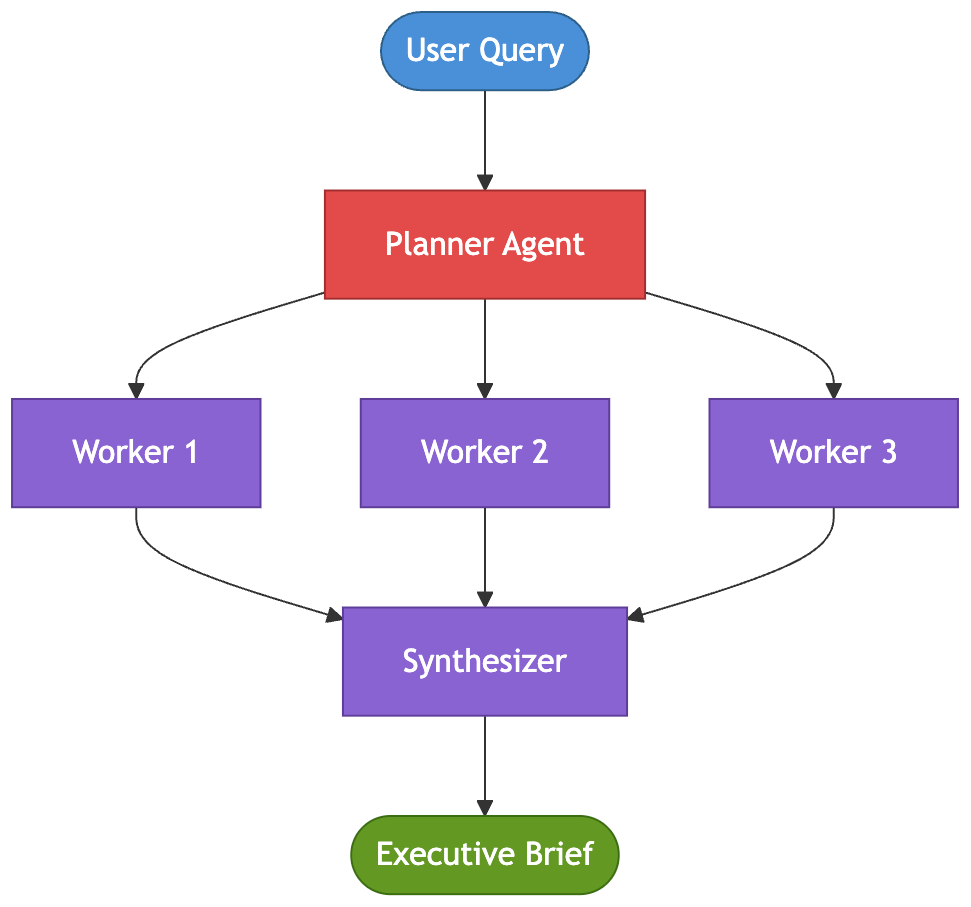
Pattern 8: Hierarchical Task Decomposition [Month 11]
Strategy asks the AI platform team: “Which three countries should we expand into next year?” This is not a typical support task — it is a multi-dimensional research problem. No single agent can answer it reliably. The question needs to be broken down into competitive analysis, regulatory constraints, logistics feasibility, and market sizing, each requiring specialized context and reasoning.
The hierarchical decomposition pattern uses a root agent to break a complex objective into smaller, well-defined subgoals, which are then delegated to specialized worker agents. Once the work is complete, the root agent synthesizes the outputs into a coherent recommendation. This pattern works best when the problem is too broad for a single reasoning pass but can be decomposed into independent areas of expertise.
import json
from dataclasses import dataclass
@dataclass
class Workstream:
name: str
deliverable: str
questions: list[str]
@dataclass
class ResearchBrief:
goal: str
workstreams: list[Workstream]
reports: list[str]
synthesis: str
class MarketExpansionResearchAgent(BaseLLMAgent):
"""Decomposes a research goal into workstreams, executes each, and synthesizes results."""
PLAN_SCHEMA = {
"type": "object",
"properties": {
"workstreams": {
"type": "array",
"items": {
"type": "object",
"properties": {
"name": {"type": "string"},
"deliverable": {"type": "string"},
"questions": {"type": "array", "items": {"type": "string"}},
},
"required": ["name", "deliverable", "questions"],
"additionalProperties": False,
},
}
},
"required": ["workstreams"],
"additionalProperties": False,
}
def _plan(self, goal: str) -> list[Workstream]:
result = self._structured(
"Break a market expansion research goal into 3 to 5 independent workstreams. "
"Each workstream must have a clear deliverable and 2-4 focused questions.",
goal,
self.PLAN_SCHEMA,
)
return [Workstream(**ws) for ws in result["workstreams"]]
def _execute_workstream(self, ws: Workstream) -> str:
return self._text(
"You are a specialist research agent. Answer only the assigned workstream. "
"List assumptions and evidence gaps separately. Be specific.",
json.dumps({"name": ws.name, "deliverable": ws.deliverable, "questions": ws.questions}),
)
def _synthesize(self, goal: str, reports: list[str]) -> str:
combined = "\\\\n\\\\n".join(
f"--- Workstream {i+1} ---\\\\n{r}" for i, r in enumerate(reports)
)
return self._text(
"Synthesize specialist research reports into an executive brief. "
"Highlight conflicts between workstreams, unsupported assumptions, and missing evidence.",
f"Goal: {goal}\\\\n\\\\nWorkstream reports:\\\\n{combined}",
)
def run(self, goal: str) -> ResearchBrief:
workstreams = self._plan(goal)
reports = [self._execute_workstream(ws) for ws in workstreams]
synthesis = self._synthesize(goal, reports)
return ResearchBrief(goal=goal, workstreams=workstreams, reports=reports, synthesis=synthesis)When to Use and When it Breaks:

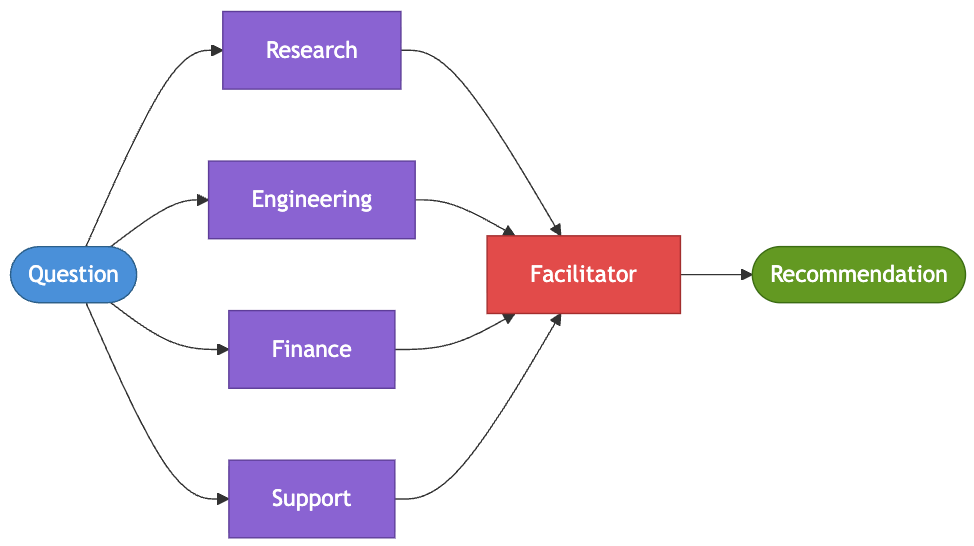
Pattern 9: Swarm [Month 12]
The product team faces a contentious question: should they launch a subscription tier? Research suggests customers want it. Engineering estimates six months of billing infrastructure work. Finance questions whether the unit economics make sense, while Support expects a spike in customer confusion and ticket volume. Every perspective is valid, but the team needs a way to surface the trade-offs before leadership makes a decision.
The swarm pattern allows multiple specialized agents to contribute to a shared working context. Each agent brings a different perspective, challenges assumptions, and adds supporting evidence. Once enough signal has accumulated, a facilitator agent synthesizes the discussion into a recommendation. This pattern works best when the goal is not a single “correct” answer, but a well-reasoned decision shaped by competing viewpoints.
from dataclasses import dataclass
@dataclass
class DebateResult:
question: str
transcript: str
recommendation: str
class ProductDecisionSwarm(BaseLLMAgent):
"""Runs a structured debate across specialist perspectives before synthesizing a recommendation."""
ROLES: dict[str, str] = {
"research": "You represent user research. Cite evidence, customer segments, and unmet needs. Challenge unsupported claims.",
"engineering": "You represent engineering. Assess feasibility, complexity, risks, and maintenance burden.",
"finance": "You represent finance. Evaluate pricing, margin, cost, and opportunity cost.",
"support": "You represent customer support. Assess operational burden, edge cases, and customer confusion risks.",
}
def run(self, question: str, rounds: int = 2) -> DebateResult:
transcript = f"Decision question: {question}\\\\n"
for round_no in range(1, rounds + 1):
for name, role_prompt in self.ROLES.items():
contribution = self._text(
role_prompt + " Respond to the current transcript. "
"Add new evidence or challenge a specific weak claim. Be concise and specific.",
transcript,
)
transcript += f"\\\\n[{name}, round {round_no}]\\\\n{contribution}\\\\n"
recommendation = self._text(
"You are a neutral decision facilitator. Review the full debate. "
"Summarize the strongest arguments, identify unresolved risks, and state a final recommendation. "
"Do not add new claims — only synthesize what is already in the transcript.",
transcript,
)
return DebateResult(question=question, transcript=transcript, recommendation=recommendation)When to Use and When it Breaks:

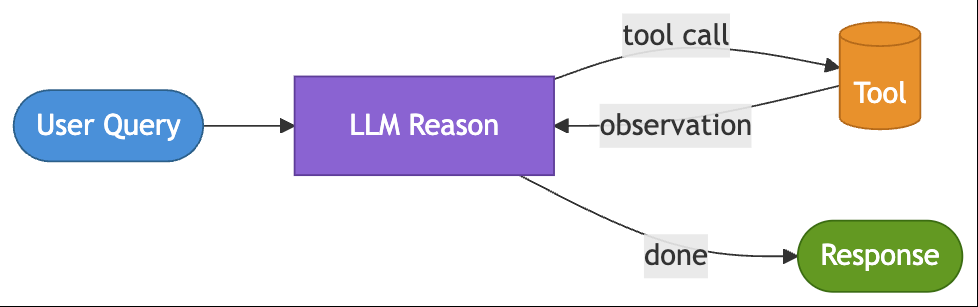
Pattern 10: ReAct (Reason and Act) [Month 13]
The DevOps team builds an internal troubleshooting assistant. When an engineer reports that “the queue processor seems stuck,” the assistant should search documentation, check service health, correlate symptoms, and only then suggest a fix. The investigation path cannot be predefined — it depends entirely on what the system uncovers along the way.
The ReAct pattern alternates between reasoning and action: deciding what to investigate, invoking a tool, observing the result, and determining whether there is enough evidence to proceed or answer. The most valuable output is not the hidden reasoning itself — it is the action trace, which makes the investigation observable, debuggable, and easier to trust in production.
import json
from dataclasses import dataclass
@dataclass
class TroubleshootingResult:
answer: str
action_trace: list[dict]
class KnowledgeBaseTroubleshootingAgent(BaseLLMAgent):
"""Iteratively calls tools to gather evidence before stating a root cause."""
SYSTEM_PROMPT = (
"You are a troubleshooting agent. Use tools to gather evidence. "
"Return the likely cause, your confidence level, and the next safe action. "
"Do not speculate beyond what the tools returned."
)
TOOLS = [
{
"type": "function",
"name": "search_docs",
"description": "Search internal troubleshooting documentation by keyword.",
"parameters": {
"type": "object",
"properties": {"query": {"type": "string"}},
"required": ["query"],
"additionalProperties": False,
},
},
{
"type": "function",
"name": "get_service_status",
"description": "Get current operational status and recent incidents for a service.",
"parameters": {
"type": "object",
"properties": {"service": {"type": "string"}},
"required": ["service"],
"additionalProperties": False,
},
},
]
def _search_docs(self, query: str) -> dict:
return {"matches": ["Restart workers after QUEUE_URL change", "Check IAM permission sqs:SendMessage"]}
def _get_service_status(self, service: str) -> dict:
return {"service": service, "status": "degraded", "since": "2026-05-21T09:20:00Z"}
def _dispatch_tool(self, name: str, args: dict) -> dict:
if name == "search_docs":
return self._search_docs(**args)
if name == "get_service_status":
return self._get_service_status(**args)
return {"error": f"Unknown tool: {name}"}
def run(self, problem: str, max_turns: int = 5) -> TroubleshootingResult:
messages = [
{"role": "system", "content": self.SYSTEM_PROMPT},
{"role": "user", "content": problem},
]
action_trace = []
for _ in range(max_turns):
response = self.client.responses.create(
model=self.model, input=messages, tools=self.TOOLS
)
calls = [item for item in response.output if item.type == "function_call"]
if not calls:
return TroubleshootingResult(answer=response.output_text, action_trace=action_trace)
messages += response.output
for call in calls:
args = json.loads(call.arguments)
result = self._dispatch_tool(call.name, args)
action_trace.append({"tool": call.name, "args": args, "result": result})
messages.append({
"type": "function_call_output",
"call_id": call.call_id,
"output": json.dumps(result),
})
return TroubleshootingResult(
answer="Investigation limit reached without sufficient evidence.",
action_trace=action_trace,
)
When to Use and When it Breaks:

Pattern 11: Human-in-the-Loop [Month 14]
The finance team wants to automate refund approvals, but only for low-risk, clear-cut cases. Requests involving high amounts, fraud signals, or policy exceptions still require human approval. The agent’s role is to investigate the case, gather context, and recommend an action — the final decision remains with a person.
This pattern is not just a UI workflow — it is an architectural decision. You need durable state, reviewer assignment, approval logs, timeout handling, escalation paths, and safe recovery mechanisms. The agent’s responsibility is to prepare evidence and hand off context, not pause indefinitely waiting for a human response.

import json
from dataclasses import dataclass
@dataclass
class HumanApproval:
approved: bool
reviewer: str
comment: str
@dataclass
class RefundOutcome:
recommendation: str
approval: HumanApproval
customer_response: str
class RefundApprovalAgent(BaseLLMAgent):
"""Investigates refund request, prepares recommendation, pauses for human approval."""
def _lookup_context(self, order_id: str) -> dict:
# Replace with real payment service call
return {
"order_id": order_id,
"amount": 420.00,
"days_since_purchase": 12,
"prior_refunds": 0,
"fraud_score": 0.02,
}
def _build_recommendation(self, customer_message: str, context: dict) -> str:
return self._text(
"You are a refund operations agent. Recommend approve, deny, or request more information. "
"Cite specific policy facts. Do not approve if fraud score exceeds 0.1.",
f"Customer message:\\\\n{customer_message}\\\\n\\\\nOrder context:\\\\n{json.dumps(context)}",
)
def _request_human_approval(self, recommendation: str) -> HumanApproval:
# In production: create a review task in the ops queue (Slack, Jira, internal tool).
# Block until approved or timed out. This stub simulates a reviewer response.
return HumanApproval(
approved=False,
reviewer="ops-manager",
comment="Ask customer for photos of the damaged item first.",
)
def _draft_customer_response(self, recommendation: str, approval: HumanApproval) -> str:
review_summary = json.dumps({"approved": approval.approved, "comment": approval.comment})
return self._text(
"Draft a customer-safe response based on the manager's review decision. "
"Do not claim the refund is approved unless it is. Be empathetic but accurate.",
f"Agent recommendation:\\\\n{recommendation}\\\\n\\\\nHuman review:\\\\n{review_summary}",
)
def run(self, order_id: str, customer_message: str) -> RefundOutcome:
context = self._lookup_context(order_id)
recommendation = self._build_recommendation(customer_message, context)
approval = self._request_human_approval(recommendation)
customer_response = self._draft_customer_response(recommendation, approval)
return RefundOutcome(
recommendation=recommendation,
approval=approval,
customer_response=customer_response,
)
When to Use and When it Breaks:

Pattern 12: Plan-and-Execute [Month 15]
The DevOps team wants an agent that can handle multi-step infrastructure operations from a natural language request: “Resize the worker fleet from 10 to 20 instances, verify the queue drains, and update the runbook.” The objective is clear, but the exact execution path depends on what the system discovers at each step.
The Plan-and-Execute pattern separates planning from execution. A planner agent first reasons about the strategy and produces a structured task plan before any action is taken. This plan can be reviewed, modified, or approved by humans. An executor agent then carries out the steps one at a time, adapting as needed during execution.

This differs from hierarchical decomposition, where tasks are recursively broken into subgoals. Here, planning is a one-time decomposition into an execution plan. It also differs from ReAct — the entire plan is visible upfront, rather than emerging incrementally through action and observation.
import json
from dataclasses import dataclass
@dataclass
class ExecutionStep:
step_id: int
action: str
tool: str
parameters: dict
expected_outcome: str
@dataclass
class ExecutionPlan:
goal: str
steps: list[ExecutionStep]
@dataclass
class ExecutionResult:
plan: ExecutionPlan
step_results: list[dict]
summary: str
class PlanAndExecuteAgent(BaseLLMAgent):
"""Generates a structured plan before taking any actions, then executes step by step."""
PLAN_SCHEMA = {
"type": "object",
"properties": {
"steps": {
"type": "array",
"items": {
"type": "object",
"properties": {
"step_id": {"type": "integer"},
"action": {"type": "string"},
"tool": {"type": "string", "enum": ["resize_fleet", "check_queue_depth", "update_runbook"]},
"parameters": {"type": "object", "additionalProperties": {"type": "string"}},
"expected_outcome": {"type": "string"},
},
"required": ["step_id", "action", "tool", "parameters", "expected_outcome"],
"additionalProperties": False,
},
}
},
"required": ["steps"],
"additionalProperties": False,
}
def _plan(self, goal: str) -> ExecutionPlan:
result = self._structured(
"Create a step-by-step execution plan for the given infrastructure task. "
"Order steps by dependency. Use only available tools.",
goal,
self.PLAN_SCHEMA,
)
steps = [ExecutionStep(**s) for s in result["steps"]]
return ExecutionPlan(goal=goal, steps=steps)
def _execute_step(self, step: ExecutionStep) -> dict:
# Real implementation would dispatch to infrastructure APIs
return {"step_id": step.step_id, "status": "completed", "output": f"Executed: {step.action}"}
def _summarize(self, plan: ExecutionPlan, results: list[dict]) -> str:
return self._text(
"Summarize the execution results. Flag any steps that did not complete as expected.",
f"Goal: {plan.goal}\\\\n\\\\nResults:\\\\n{json.dumps(results, indent=2)}",
)
def run(self, goal: str) -> ExecutionResult:
plan = self._plan(goal)
step_results = []
for step in plan.steps:
result = self._execute_step(step)
step_results.append(result)
# In production: halt here if the step failed; surface for human review
if result.get("status") != "completed":
break
summary = self._summarize(plan, step_results)
return ExecutionResult(plan=plan, step_results=step_results, summary=summary)When to Use and When it Breaks:

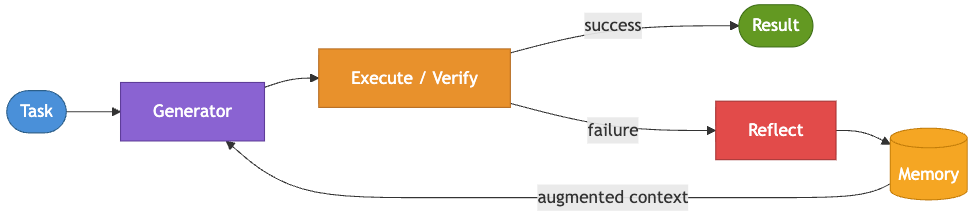
Pattern 13: Reflexion [Month 16]
The data team asks the AI platform to generate Python scripts for one-off data transformations. The first attempt often compiles successfully but breaks at runtime, usually on edge cases or unexpected inputs. Instead of escalating failures to a human, the team wants the agent to analyze the error, understand what went wrong, and retry with a better approach.
The Reflexion pattern gives agents the ability to learn from their own failures. Unlike a standard loop pattern, where retries are driven by an external judge, the agent evaluates its own output, reflects on the failure, and records observations about what went wrong. That memory then directly influences the next attempt, improving performance over time rather than repeating the same mistake.
import json
from dataclasses import dataclass
@dataclass
class ReflexionMemory:
attempt: int
output: str
error: str | None
reflection: str
@dataclass
class ReflexionResult:
final_output: str
memory: list[ReflexionMemory]
succeeded: bool
class ReflexionCodingAgent(BaseLLMAgent):
"""Generates code, simulates execution, reflects on failures, and retries with accumulated memory."""
REFLECTION_SCHEMA = {
"type": "object",
"properties": {
"succeeded": {"type": "boolean"},
"error_analysis": {"type": "string"},
"what_to_fix": {"type": "string"},
},
"required": ["succeeded", "error_analysis", "what_to_fix"],
"additionalProperties": False,
}
def _generate(self, task: str, memory: list[ReflexionMemory]) -> str:
memory_context = "\\\\n\\\\n".join(
f"Attempt {m.attempt}: FAILED\\\\nError: {m.error}\\\\nReflection: {m.reflection}"
for m in memory
if m.error
)
return self._text(
"Write a Python function for the given data transformation task. "
"Handle edge cases explicitly. Learn from past failures.",
f"Task:\\\\n{task}\\\\n\\\\nPast failures:\\\\n{memory_context or 'None yet'}",
)
def _execute_and_observe(self, code: str) -> tuple[str | None, str | None]:
"""Returns (output, error). Replace with sandbox execution in production."""
try:
# Simulate execution — in production use a sandbox (e.g., subprocess, E2B)
exec_globals: dict = {}
exec(compile(code, "<agent>", "exec"), exec_globals)
return "Executed successfully", None
except Exception as e:
return None, str(e)
def _reflect(self, code: str, error: str) -> str:
result = self._structured(
"Analyze why this code failed. Identify the root cause and what should change in the next attempt.",
f"Code:\\\\n{code}\\\\n\\\\nError:\\\\n{error}",
self.REFLECTION_SCHEMA,
)
return result["what_to_fix"]
def run(self, task: str, max_attempts: int = 3) -> ReflexionResult:
memory: list[ReflexionMemory] = []
for attempt in range(1, max_attempts + 1):
code = self._generate(task, memory)
output, error = self._execute_and_observe(code)
if error is None:
memory.append(ReflexionMemory(attempt=attempt, output=code, error=None, reflection="Succeeded"))
return ReflexionResult(final_output=code, memory=memory, succeeded=True)
reflection = self._reflect(code, error)
memory.append(ReflexionMemory(attempt=attempt, output=code, error=error, reflection=reflection))
return ReflexionResult(final_output=memory[-1].output, memory=memory, succeeded=False)When to Use and When it Breaks:

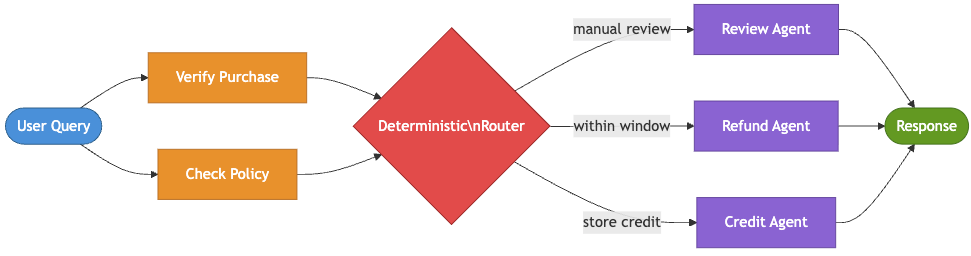
Pattern 14: Custom Logic [Month 18]
The refund workflow has outgrown every clean architectural pattern. A high-value damaged-goods refund follows a different path than a standard return. Fraud signals route cases to specialists. Some checks can run in parallel, others require human approval, and certain situations call for store credit instead of a cash refund. At this stage, the business process contains real branching logic, and those branches often carry legal or financial consequences.
The custom logic pattern combines deterministic orchestration with agentic behavior. The challenge is deciding what belongs in code and what belongs in the model. Eligibility rules, permission checks, payment actions, and safety constraints should remain deterministic and auditable. Meanwhile, tasks involving interpretation, drafting, routing recommendations, and exception handling are often where the model adds the most value.
import asyncio
import json
from dataclasses import dataclass
@dataclass
class PurchaseVerification:
order_id: str
purchased_by_user: bool
amount: float
@dataclass
class RefundPolicy:
within_window: bool
damaged_item_reported: bool
fraud_flag: bool
requires_manual_review: bool
@dataclass
class WorkflowResult:
path: str
output: str
class RefundOrchestrator(BaseLLMAgent):
"""Custom workflow: parallel checks → deterministic routing → agentic response drafting."""
async def _verify_purchase(self, order_id: str) -> PurchaseVerification:
# Replace with real payment service call
return PurchaseVerification(order_id=order_id, purchased_by_user=True, amount=89.99)
async def _evaluate_policy(self, order_id: str) -> RefundPolicy:
# Replace with real policy service call
return RefundPolicy(
within_window=False,
damaged_item_reported=True,
fraud_flag=False,
requires_manual_review=True,
)
def _draft_manual_review_packet(self, context: dict) -> str:
return self._text(
"Prepare a manual review packet for operations. "
"Include the customer claim, policy status, decision points, and missing evidence.",
json.dumps(context),
)
def _draft_refund_confirmation(self, context: dict) -> str:
return self._text(
"Draft an internal refund processing note. Include only confirmed facts from context.",
json.dumps(context),
)
def _draft_store_credit_offer(self, context: dict) -> str:
return self._text(
"Draft a customer response offering store credit. "
"Explain the policy reason clearly without being dismissive.",
json.dumps(context),
)
async def run(self, order_id: str, customer_message: str) -> WorkflowResult:
# Run eligibility checks in parallel — they are independent
purchase, policy = await asyncio.gather(
self._verify_purchase(order_id),
self._evaluate_policy(order_id),
)
context = {
"customer_message": customer_message,
"purchase": {"purchased_by_user": purchase.purchased_by_user, "amount": purchase.amount},
"policy": {
"within_window": policy.within_window,
"damaged_item_reported": policy.damaged_item_reported,
"fraud_flag": policy.fraud_flag,
},
}
# Deterministic routing — these rules must not be delegated to the model
if not purchase.purchased_by_user:
return WorkflowResult(path="denied", output="Refund denied: requester is not the purchaser.")
if policy.fraud_flag:
return WorkflowResult(path="fraud_hold", output="Refund held: fraud flag active. Routing to fraud team.")
if policy.requires_manual_review:
return WorkflowResult(path="manual_review", output=self._draft_manual_review_packet(context))
if policy.within_window:
return WorkflowResult(path="approved", output=self._draft_refund_confirmation(context))
return WorkflowResult(path="store_credit", output=self._draft_store_credit_offer(context))When to Use and When it Breaks:

Pattern 15: Event-Driven Agent
The fraud team realizes their biggest challenge is not routing, but timing. By the time a support ticket highlights suspicious activity, the opportunity to block or intervene on the transaction has often already passed. They do not need agents that wait for instructions — they need agents that react the moment something important happens.
Most patterns discussed so far are request-driven: they begin when a user or system explicitly asks for something. The event-driven pattern works differently. It is asynchronous and reactive, subscribing to event streams such as a Kafka topic, webhook, or database change feed. When a predefined condition is triggered, the agent wakes up and acts autonomously, without waiting for a human request.

import asyncio
import json
from dataclasses import dataclass
from datetime import datetime
@dataclass
class FraudEvent:
event_id: str
user_id: str
amount: float
merchant: str
timestamp: str
risk_signal: str # e.g., "velocity_spike", "new_device", "geo_anomaly"
@dataclass
class FraudDecision:
event_id: str
action: str # "block" | "flag" | "allow"
reasoning: str
triggered_at: str
class FraudDetectionAgent(BaseLLMAgent):
"""
Reacts to real-time fraud events. In production, subscribe this to a Kafka consumer
or webhook endpoint rather than calling run() directly.
"""
DECISION_SCHEMA = {
"type": "object",
"properties": {
"action": {"type": "string", "enum": ["block", "flag", "allow"]},
"reasoning": {"type": "string"},
},
"required": ["action", "reasoning"],
"additionalProperties": False,
}
async def _enrich_context(self, event: FraudEvent) -> dict:
"""Fetch user history and merchant reputation — replace with real API calls."""
return {
"user_prior_disputes": 0,
"merchant_risk_tier": "medium",
"transaction_count_last_hour": 7,
}
def _decide(self, event: FraudEvent, context: dict) -> dict:
return self._structured(
"You are a fraud risk analyst. Evaluate the transaction event and enriched context. "
"Only block when evidence is strong. Flag when uncertain. Allow when risk is low.",
f"Event:\\\\n{json.dumps(event.__dict__)}\\\\n\\\\nContext:\\\\n{json.dumps(context)}",
self.DECISION_SCHEMA,
)
async def handle_event(self, event: FraudEvent) -> FraudDecision:
context = await self._enrich_context(event)
decision = self._decide(event, context)
return FraudDecision(
event_id=event.event_id,
action=decision["action"],
reasoning=decision["reasoning"],
triggered_at=datetime.utcnow().isoformat(),
)
async def run_consumer_loop(self, event_queue: asyncio.Queue) -> None:
"""Consume events from an async queue — wire to Kafka/webhook in production."""
while True:
event = await event_queue.get()
decision = await self.handle_event(event)
# Publish decision back to event bus, audit log, or action service
print(f"[{decision.triggered_at}] {decision.event_id}: {decision.action} — {decision.reasoning}")
event_queue.task_done()When to Use and When it Breaks:

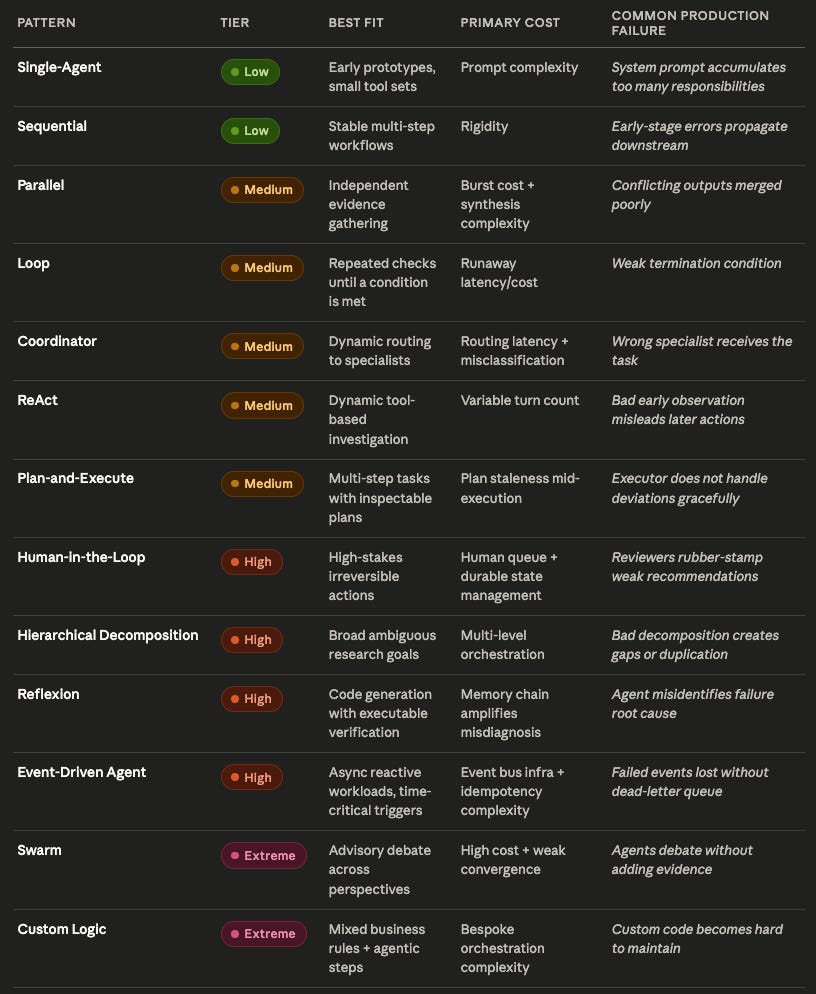
Pattern Selection Summary
Ten Rules for Production Agentic Systems
Start with the smallest pattern that works. A single agent with good tool contracts beats a multi-agent architecture with weak ones.
Give every tool a narrow schema and an honest description. Tool descriptions are not documentation — they are the model’s only source of truth about what the tool does. Write them as you would write a contract.
Cap iterations, tool calls, and total spend per request. An agent without budget limits is a liability waiting to appear in a bill review.
Log the action trace. Model request ID, selected tool, arguments, output summary, and final decision. Without this, incident investigation is guesswork.
Keep irreversible actions behind deterministic checks or human approval. A model should never be the only gate between a user input and a database write, a money movement, or a production change.
Evaluate agents with real failure cases, not just happy-path prompts. An agent that handles the happy path correctly is a prototype. An agent that handles the edge cases correctly is a product.
Separate prompts by responsibility before the system prompt becomes unreadable. When you catch yourself adding “but do not do X when Y” to a system prompt, that is a sign the agent is doing two jobs.
Treat multi-agent systems as distributed systems. Partial failure, timeouts, retries, ownership, and observability are not optional. They are the cost of autonomy.
Model review is not a substitute for deterministic validation. Use critics, judges, and reviewers to improve quality. Use tests, policy engines, permission checks, and database constraints to enforce correctness.
Prefer the simpler pattern. Not because simpler is always better — but because the complexity budget you save on the orchestration layer can be spent on the thing that actually matters: better tools, better prompts, and better evaluation.
The Right Shape
Agent design patterns are not maturity levels. A swarm is not more sophisticated than a single-agent system if the task only needs one reliable tool-using agent. A hierarchical decomposition is not better than a sequential pipeline if the business process is already stable. Plan-and-Execute is not an upgrade from ReAct if the plan will be stale before the third step.
The right pattern is the one that matches the shape of uncertainty in the work:
Uncertainty in tool choice → Single-Agent or ReAct
Uncertainty in routing → Coordinator
Uncertainty in quality → Review & Critique or Iterative Refinement
Uncertainty in execution path → Plan-and-Execute or ReAct
Uncertainty in self-correction → Reflexion or Loop
Uncertainty in business risk → Human-in-the-Loop or Custom Logic
Uncertainty in problem structure → Hierarchical Decomposition or Swarm
Uncertainty in timing (cannot wait for a user request) → Event-Driven Agent
Uncertainty in output quality at scale → LLM-as-Judge
The most reliable production systems are usually not the most autonomous ones. They are the ones that put autonomy exactly where it creates value and constrain it everywhere else.
References
Google Cloud Architecture Center, “Choose a design pattern for your agentic AI system”: https://cloud.google.com/architecture/choose-design-pattern-agentic-ai-system
Yao et al., “ReAct: Synergizing Reasoning and Acting in Language Models” (ICLR 2023)
Shinn et al., “Reflexion: Language Agents with Verbal Reinforcement Learning” (NeurIPS 2023)
Chase, “Plan-and-Solve Prompting” and LangGraph plan-and-execute documentation
Anthropic, “Building Effective AI Agents”: https://www.anthropic.com/research/building-effective-agents
OpenAI API documentation, Responses API: https://platform.openai.com/docs/api-reference/responses
OpenAI API documentation, Function calling guide: https://platform.openai.com/docs/guides/function-calling